Graph_embedding之SDNE
目标
复现SDNE,思考如何利用点击和相关属性获取合适的商品embedding,用于以后的商品聚类。
模型简介
模型结构
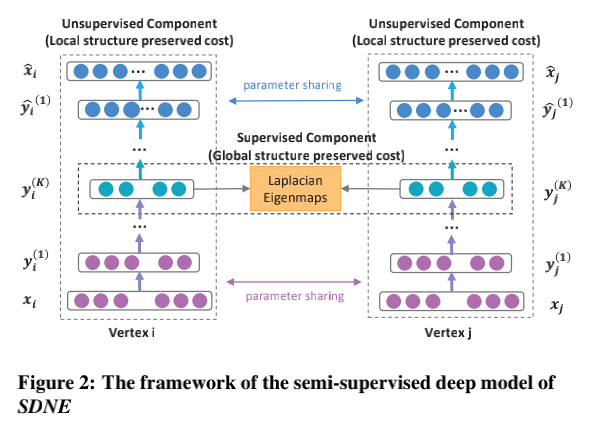
SDNE是16年发表在kdd上的一篇论文,是第一篇将深度学习模型运用于Graph embedding的论文。其可以看作LINE的一种延伸。使用一个自编码器来同时优化1阶和2阶损失,训练结束的中间向量作为商品embedding。
损失函数
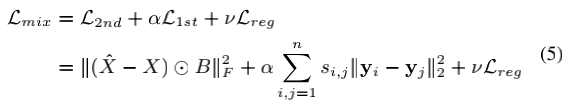
1阶损失:不同节点中间变量的相似程度,α表示控制1阶损失函数
2阶损失:同一节点重构后的差距,Β矩阵用于控制非0元素,对其实施更高的惩罚系数,避免非0元素由于反向传播变0
reg损失:控制模型参数,v正则化参数
论文核心
模型的输入:每个节点的领结矩阵,相邻节点的拉普拉斯矩阵
模型的输出:每个节点预测的领结矩阵
领接矩阵
用于表示顶点之间相邻关系的矩阵。分为有向无权,有向有权,无向无权,无向有权矩阵。
如果是无权,其实权重代表的就是两个节点之间是否相连,相连为1,不相连为0。如果是有权,权重的设定可以是多样化的,可以只用连接信息设置权重,也可以添加side_info设置综合权重【新品的话就必须加side_info】。
有向无向对于邻接矩阵没有太大的影响,无非有向的邻接是非对称矩阵,而无向的邻接是对称矩阵。
拉普拉斯矩阵
给定一个有n个顶点的图G,它的拉普拉斯矩阵。
L=D-A,其中D为图的度矩阵,A为图的邻接矩阵。度矩阵在有向图中,有向图的度等于出度和入度之和。
复现情况
修改部分
- 矩阵生成:由于原论文的复现代码都是直接生成全量的领接矩阵和拉普拉斯矩阵,但考虑实际情况,我们点击商品有30W,全量商品有100W,直接生成全量矩阵不现实,即使用半精度【FP16】至少要100多个G,而且对于深度模型而言,模型的参数无法使用半精度,会导致数值溢出问题。因此就必须改写矩阵生成模块。
- 模型内部:由于节点很多,导致输入输出的参数非常庞大,因此无法设置过多的层数和较大的embedding维度。这个暂时无法改变,只能限制网络结构用GPU跑动
- 损失函数:按原论文增加了正则化损失
- 图的生成:参考浮现的代码只构造了有向图的领接矩阵,为了综合比较,构造了无向图的数据模块。
原始数据
参数:
- 数据集:wiki
- epoch:5/10/20/50
- 其他参数均一样
| base_epoch5 | base_epoch10 | base_epoch20 | base_epoch50 | rec_epoch5 | rec_epoch10 | rec_epoch20 | rec_epoch50 | |
|---|---|---|---|---|---|---|---|---|
| micro_f1 | 0.4137 | 0.4927 | 0.6216 | 0.5717 | 0.5841 | 0.6267 | 0.7190 | 0.7072 |
| macro_f2 | 0.2788 | 0.3417 | 0.4479 | 0.4187 | 0.3640 | 0.4208 | 0.5154 | 0.5510 |
小点分析:重构代码效果正常,增加了正则化损失在该数据集更有用
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 ShiHai'Blog!

评论