万物皆可embedding
万物皆可embedding
前言
本文的目的是想通过这次分享,让可爱学长们能够了解在算法人员口中的embedding到底是什么,它是如何作用在我们算法的日常工作中。
背景
引入embedding之前,需要先讲一下embedding的前身技术,one-hot编码。
one-hot
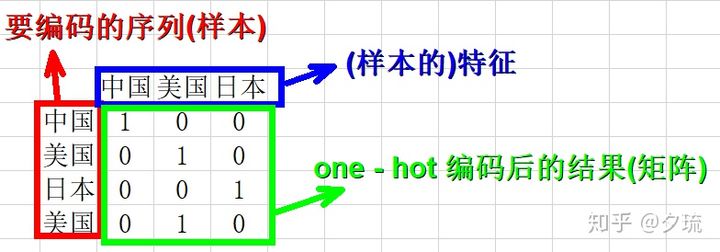
在机器学习里,存在one-hot向量(英语:one-hot vector)的概念。在一任意维度的向量中,仅有一个维度的值是1,其余为0。譬如向量[0,0,1,0,0],即为5维空间中的一组one-hot向量。将类别型数据转换成one-hot向量的过程则称one-hot编码(英语:one-hot encoding。在统计学中,one-hot我们一般叫做虚拟变量。
优势
- 可以将类别型数据转化为向量形式,各类别在高维空间中距离相等
- 进行损失函数(例如交叉熵损失)或准确率计算时,变得非常方便
劣势
- 当类别数量过于庞杂时,会导致维度灾难
- 不能很好的刻画词与词之间的相似性
- 强稀疏性
备注
- sklearn包:sklearn.preprocessing.OneHotEncoder
- pandas包:pandas.get_dummies
embedding
为了克服上述缺点,embedding技术就横空出世,最开始应用于NLP的词表达中,其最早时在1986年Hinton提出的,其基本想法是:
通过训练将某种语言中的每一个词 映射成一个固定长度的短向量(当然这里的“短”是相对于One-Hot的“长”而言的),所有这些向量构成一个词向量空间,而每一个向量则可视为 该空间中的一个点,在这个空间上引入“距离”,就可以根据词之间的距离来判断它们之间的语法、语义上的相似性。
真正让embedding技术发扬光大的是谷歌Tomas Mikolov团队的Word2Vec工具。该工具效率很高并且在语义表示上具有很好的效果。
时至今日,embedding技术延伸至生活的方方面面,现在我们可以用embedding技术去表达一部电影,一个用户,一个商品等等。
说了这么多,那到底什么是embedding技术,一句话概括:一种基于低维向量来表示物品的技术我们称之为embedding技术。
Word2vec
word2vec模型的目的并不是训练词embedding,词embedding只是模型的附带品!!!
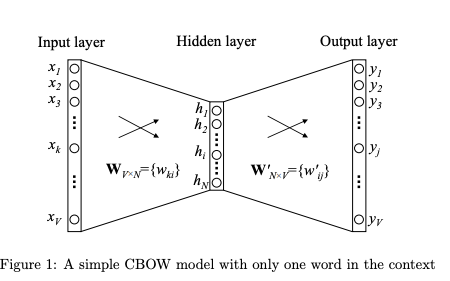
模型结构
- 两层浅层神经网络
- 输入单词,输出预测单词的概率
两种训练模式
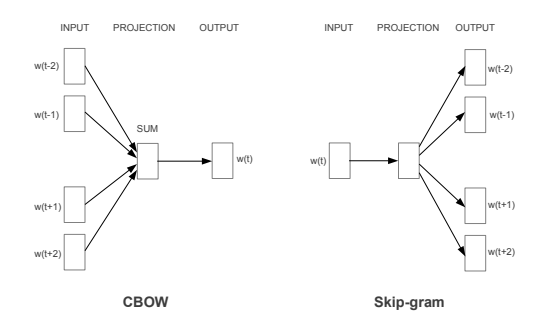
CBOW
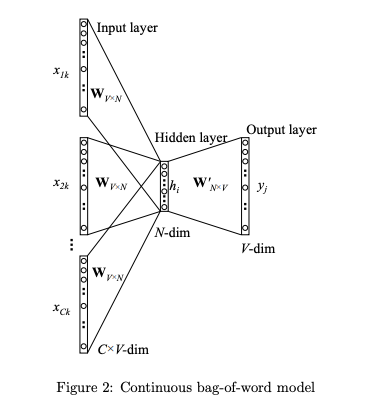
通过上下文来预测当前值。相当于一句话中扣掉一个词,让你猜这个词是什么。
Skip-gram
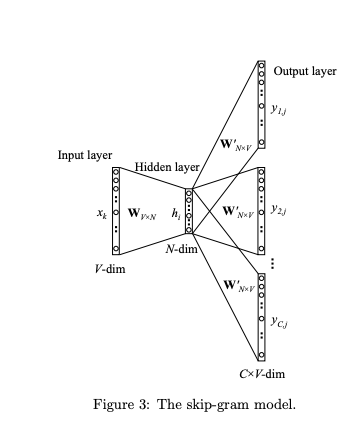
用当前词来预测上下文。相当于给你一个词,让你猜前面和后面可能出现什么词。
两种优化方式
前文说了,Word2vec的输出是预测单词的概率,这是利用Softmax函数做归一化去处理的,那我们来看看softmax是什么。
那我们看到Softmax需要经历指数计算,指数计算在计算机运算中效率并不高,并且还需要计算全部单词的概率,当单词量级很高的时候,效率就会非常低,因为针对训练提出了两种优化方式:层序softmax和负采样。
Hierarchical Softmax
利用霍夫曼树代替从隐藏层到输出softmax层的映射,霍夫曼树简单来说就是:权重【频率】越低的单词优先合并成根节点的原则生成一整颗二叉树,大家可以看下图
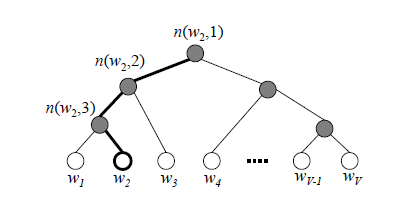
如果输入样本输出的真实值是W2,那么Hierarchical Softmax利用逻辑回归分类器一层一层做而分类,综合每一层的逻辑回归作为目标函数进行训练。(层序softmax就是一层一层做分类得来的)
优点
- 既然是二叉树,那计算量就从V变成了logV。
- 针对高频词,路径越短,计算越快。
缺点
当中心词是偏僻词时,路径会很长,训练时间提高
Negative Sampling
Negative Sampling(负采样)的原理就比较简单,事先选择5-20个单词作为负样本,将softmax函数改为sigmod函数,直接由多分类作为二分类来使用。(至于负采样的个数,利用什么样的策略采样本文不予展开)
优点
- 不用构造霍夫曼树,只需要维护一个负样本数据集
- 将softmax修改为sigmod函数,只需要改变第二层神经网络的少量参数,大大提升了效率
优缺点
优点
- 经过速度优化以后,训练词向量的速度很快
- 通用性很强,可以用在各种 NLP 任务中
- 由于考虑上下文,因此效果再18年以前一直都是Embedding技术的王牌
缺点
- 由于词和向量是一对一的关系,所以多义词的问题无法解决
- Word2vec 是一种静态的方式,虽然通用性强,但是无法针对特定任务做动态优化
问题
- 为什么要用CBOW和Skip-gram两种方式来训练,而不直接用传统DNN来训练?
- CBOW和Skip-gram分别有什么优劣势?
应用
Word embedding及其衍生
用于表示单词于单词之间的相关性【基础任务】
- Word2vec【2013】:NLP中词向量训练的鼻祖
- Fasttext【2014】:Word2vec基础上引入了字符级别的词向量,对德语,俄语更友好
- ELMO【2018】:解决了一次多义的词向量模型
- Embedding layer【Bert时代】:基于Bert后时代的模型,词向量已经不作为单独训练的目的,而是直接作为输入的一层嵌入模型中,跟随任务目标的变化而变化
- Item2vec【2016】:微软将word2vec应用于推荐领域的一篇实用性很强的文章,主要用于训练item embedding,但更重要的是使其从NLP领域直接扩展到推荐、广告、搜索等任何可以生成sequence的领域。
- Airbnb Embedding【2018】:Airbnb将word2vec用于推荐的典型文章,主要用于训练user embedding,很多user look alike系统的user embedding都是这么训练来的。
Sentence embedding
用于表示句子于句子之间的相关性【标题召回】
- Doc2vec【2014】:在Word2vec的基础上引入一个句向量概念,随着模型一起训练
- Sentence_Bert【2019】:以Bert为基础,用有监督数据训练词向量
- SimCSE/ConSert/EsimCSE【2021】:对比学习方法,利用Sentence_Bert进行自监督训练
Graph embedding
节点映射为向量表示的时候尽可能多地保留图的拓扑信息【社区关系】
- Deepwalk/Line/Node2Vec:基于Skip-gram的节点向量训练模型,区别在于他的输入需要用不同的遍历方式构造序列
- SDNE【2016】:基于自编码器的半监督Graph embedding训练模型,可以看作Line的一种延伸
- GCN/GraphSAGE/GAT/GIN【GCN时代】:GCN类模型,现阶段Graph embedding效果最好的模型
- EGES【2018】:很好用的item emebdding训练模型,其原理就是deepwalk+不同的sideinfo形成商品embedding用于推荐搜索
问题
- 什么是Embedding?
- Embedding如何作用在我们算法工作?
